원래 서비스와 완전히 분리가 일단 불가능한 상태에서 한 feature가 MSA로 나가는 상황.
feature에서 데이터가 create되면 그 함수에서 event를 만들어 카프카로 보내게 만들었다. 그리고 그 카프카 이벤트를 MSA의 feature가 컨슘하게 되고 데이터는 MSA의 DB로 저장되게 된다.
create 발생, event 생성 -> Kafka -> MSA -> DB
일단 이 방식으로 잘 동작하는 건 확인했고, 이제 모든 CRUD 에서 이 로직이 동작하게끔 해야하는데 여기서 문제가 생겼다.
레거시 코드가 너무 거대했다. update 함수가 수십개에 달하고 그 update 로직들이들이 어디있는지 모두 찾기가 어려웠다.

업데이트 로직이 컨트롤러에도 있고, 뭔가 알 수 없는 서비스에서도 업데이트가 일어나는 것 같았다.
불가능한 방법은 아니지만 수십개의 함수를 모두 찾는건 힘들어보였고, 이벤트를 보내는 함수를 모두 복붙해넣는 것도 그렇게 좋은 방법이라고 생각되지 않았다.
크론잡으로 주기적으로 DB를 조회하는 방법도 생각해봤는데 이건 딱 봐도 너무 쿼리를 많이 하는 것처럼 느껴져 바로 다른 방법을 강구했다.
애초부터 업데이트 로직을 하나로 뭉쳐놨으면 이런 일은 없었겠지만, 그럼 다른 곳에서 로직이 뭉쳐져 있지 않을까 해서 생각해낸 방법이다.
beego라는 orm을 쓰고 있는데 모든 update는 orm을 통해서 이루어지기 때문에 orm 자체를 변경하면 가능하지 않을까한 방식이다. 일종의 custom orm이라고 할까? 나쁘지 않아보이긴 하는데 이렇게 하면 상상조차 가지 않는 엄청난 데이터가 모두 내가 원하는 테이블의 데이터인지 검사(?)해야하니 뭔가 불쾌한 느낌이 들었다.
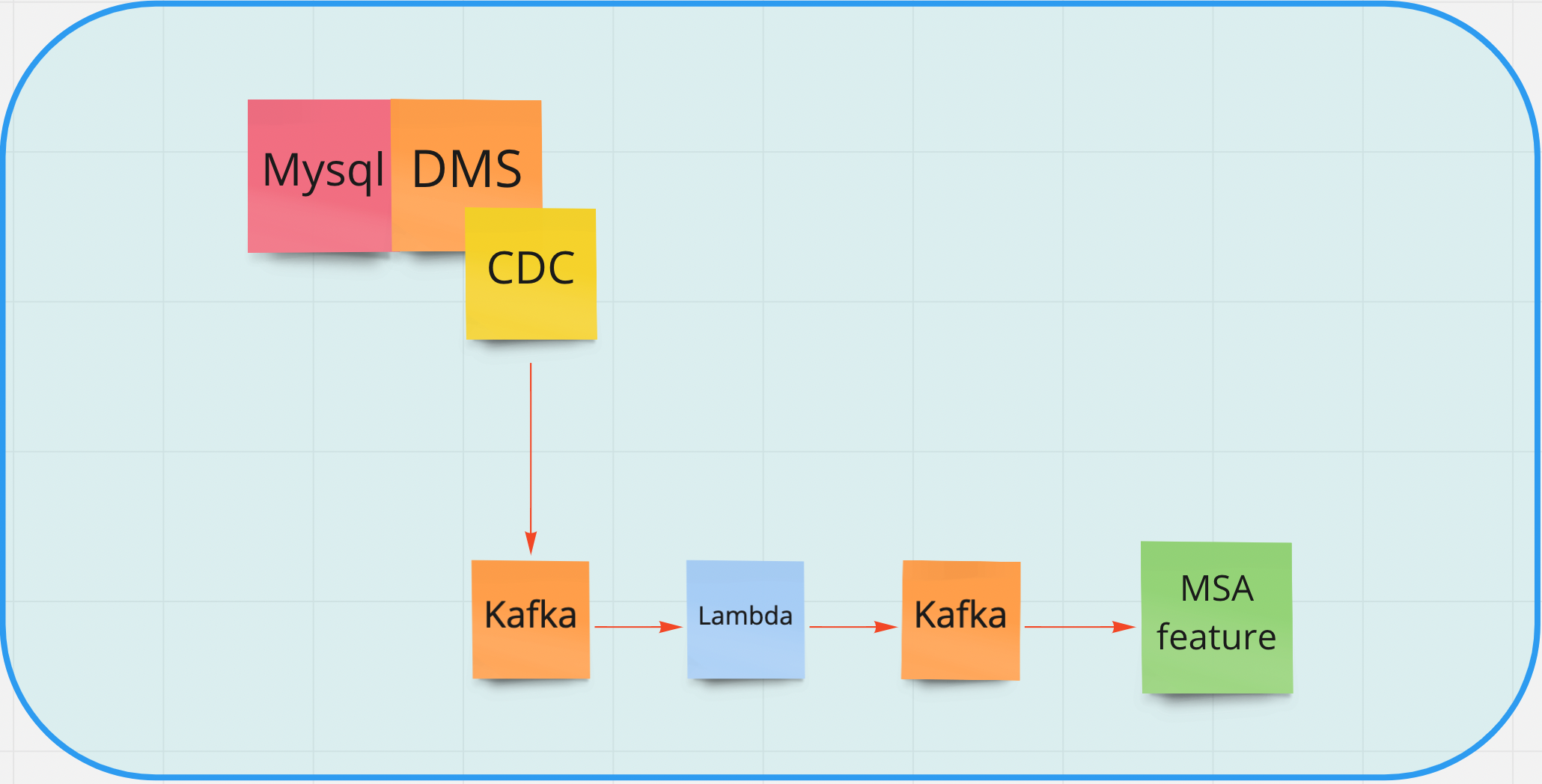
그렇다면 DB자체에서 원하는 테이블의 데이터 변경이 이루어지는 것을 감지해서 하면 어떨까?
언뜻 보기엔 가장 이상적인 방법으로 보였다.
알아보니 DMS에 CDC 플러그인으로 내가 원하는 테이블(컬럼 단위까지 가능)의 변경을 이벤트로 발행하는게 가능했다.
실제로 데비지움이라는 CDC를 쓰고 있었기에 괜찮은 방법이라고 생각했다.
하지만 그만큼 아키텍쳐가 무거워지고, 실제로는 어떻게 될지 또 모르기 때문에 그에 대한 부담감도 상당히 클 것으로 예상된다.
아직 어떻게 해야할지 정확하게 정해진 건 없지만 여러가지 생각을 해보고 조언을 구하고 있다.
'개발일기' 카테고리의 다른 글
| 자고 일어나니 회사가 사라졌다 (0) | 2022.08.31 |
|---|---|
| 유니티 게임 개발 마무리 (1) | 2022.07.17 |
| 데이터 엔지니어, 데이터 애널리스트, 데이터 사이언티스트 무엇이 다를까 (0) | 2022.05.01 |
| 머신러닝 스터디에 가입하다 (3) | 2022.04.15 |
| DB에 쿼리 날리지 마라 (0) | 2021.12.20 |




댓글