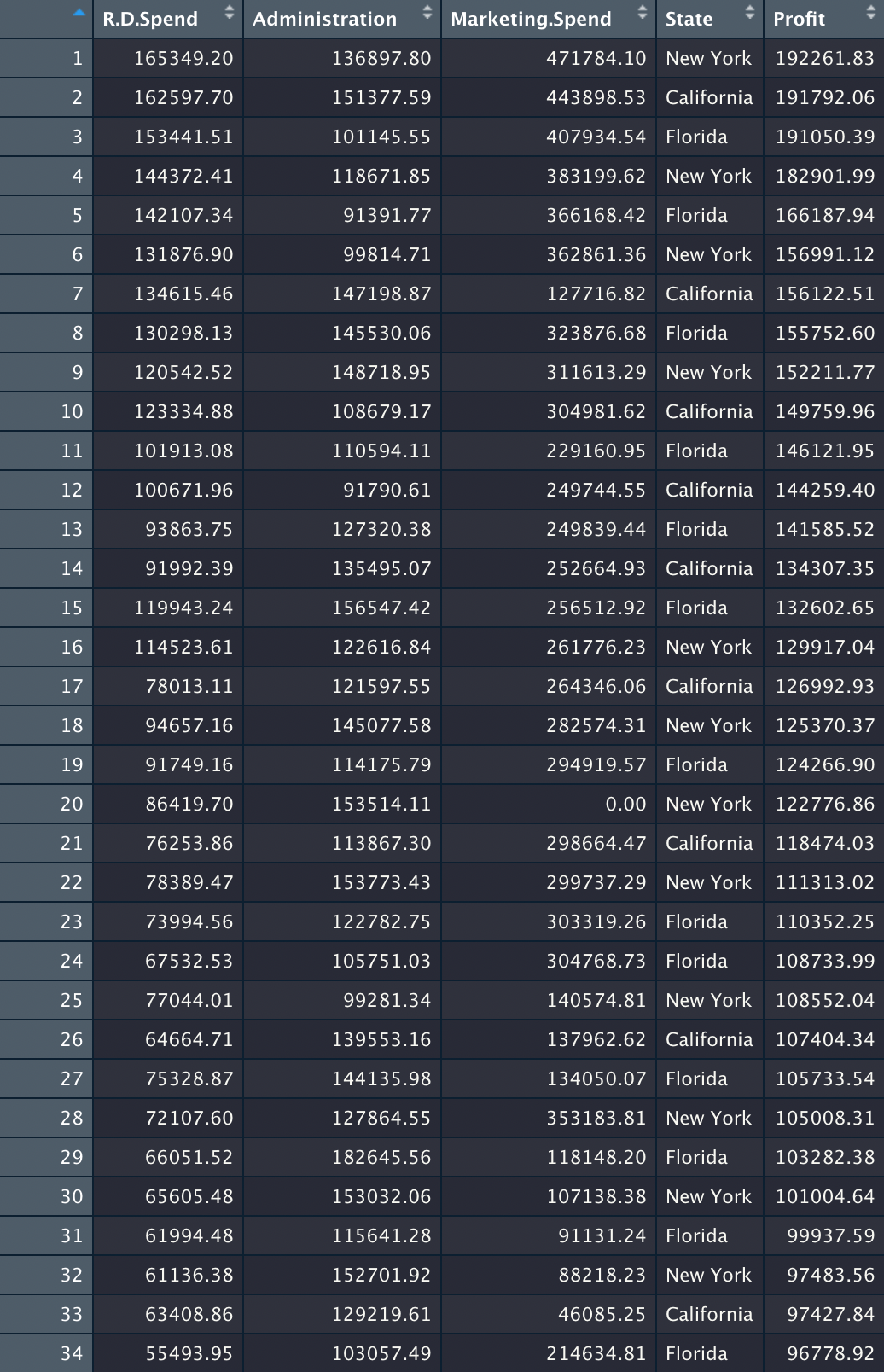
regressor = lm(formula = Profit ~ ., #.은 모든 독립변수들을 뜻 함
data = training_set)독립 변수 : R.D.Spend(연구개발 비용), Administration(행정 비용), Marketing.Spend(마케팅 비용), State(주)
종속 변수 : Profict(이익)
이 데이터를 바탕으로 스타트업들의 미래 이익을 예측하고, 어떤 독립 변수가 이익에 가장 큰 이익을 주는지 알아내고, 어떤 부분이 이익과 독립 변수 사이의 관계를 주도하는지 하는 정보들을 알아볼 것이다.
먼저 앞서 데이터 전처리에서 배운대로 범주형 데이터를 양적 데이터로 변경해준다.
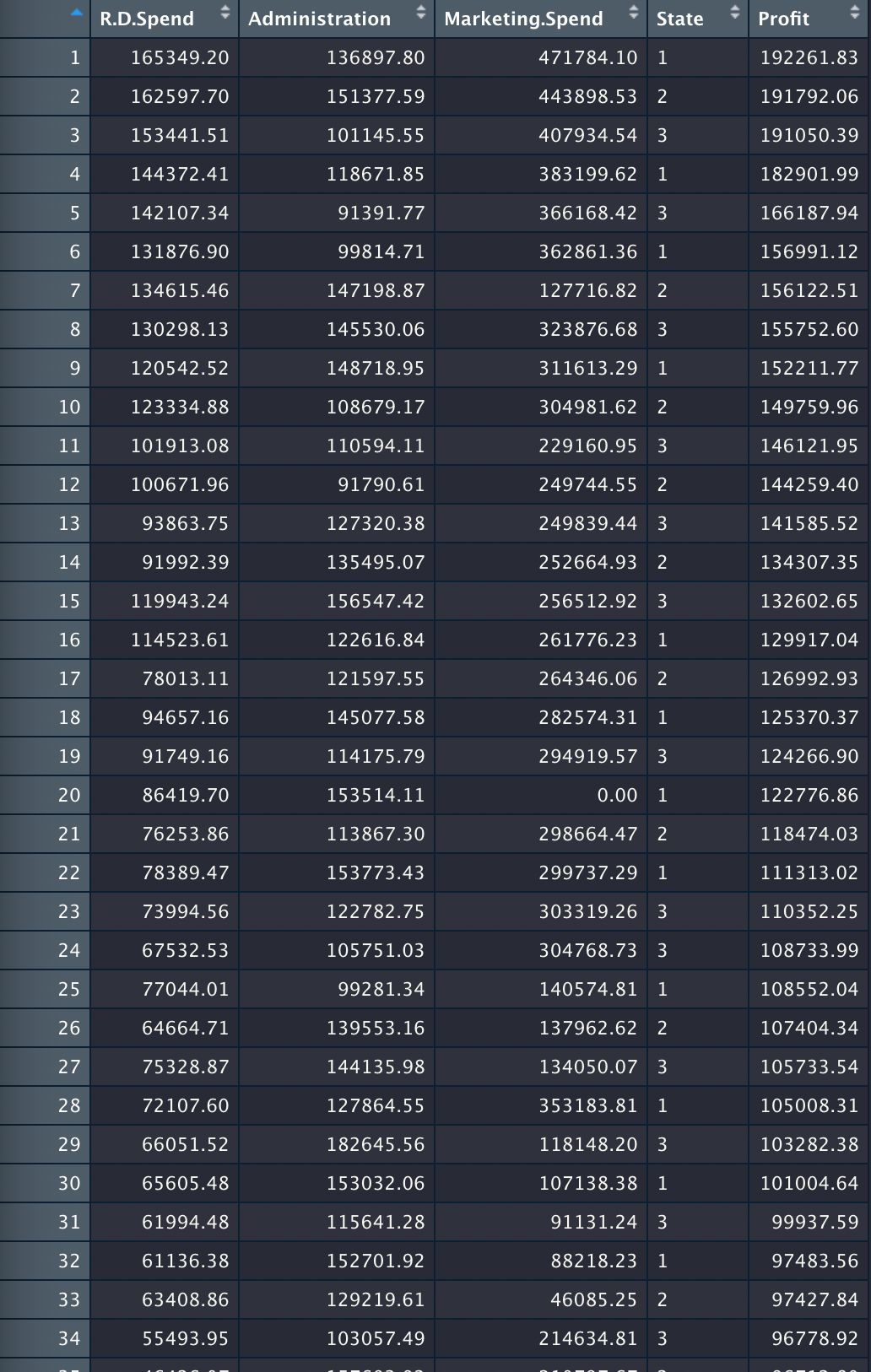
다음으로 역시 앞에서 배운대로 훈련 세트와 테스트 세트로 나눈다.
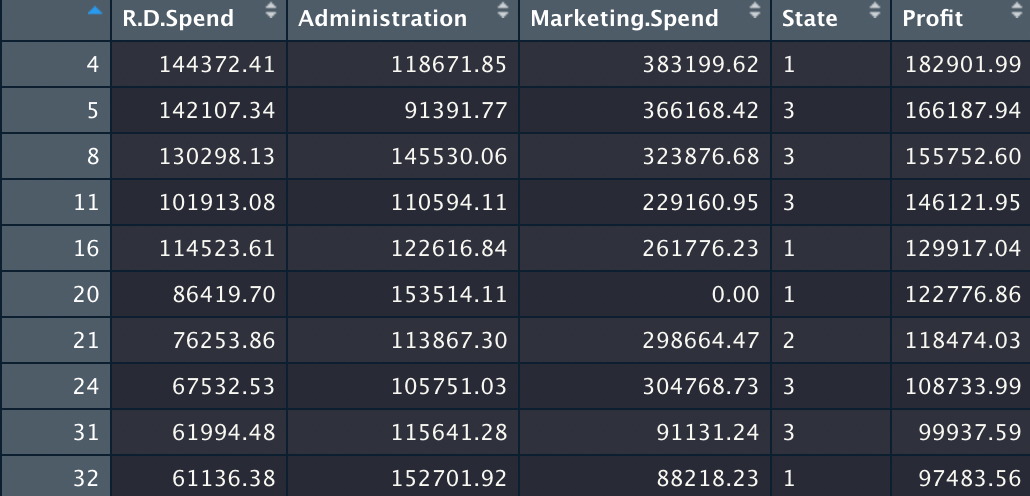
다음에 나와있는 코드로 훈련 세트를 다중 선형 회귀에 맞춰주고, regressor의 정보를 본다.
regressor = lm(formula = Profit ~ ., # .은 모든 독립변수들을 뜻 함
data = training_set)
summary(regressor)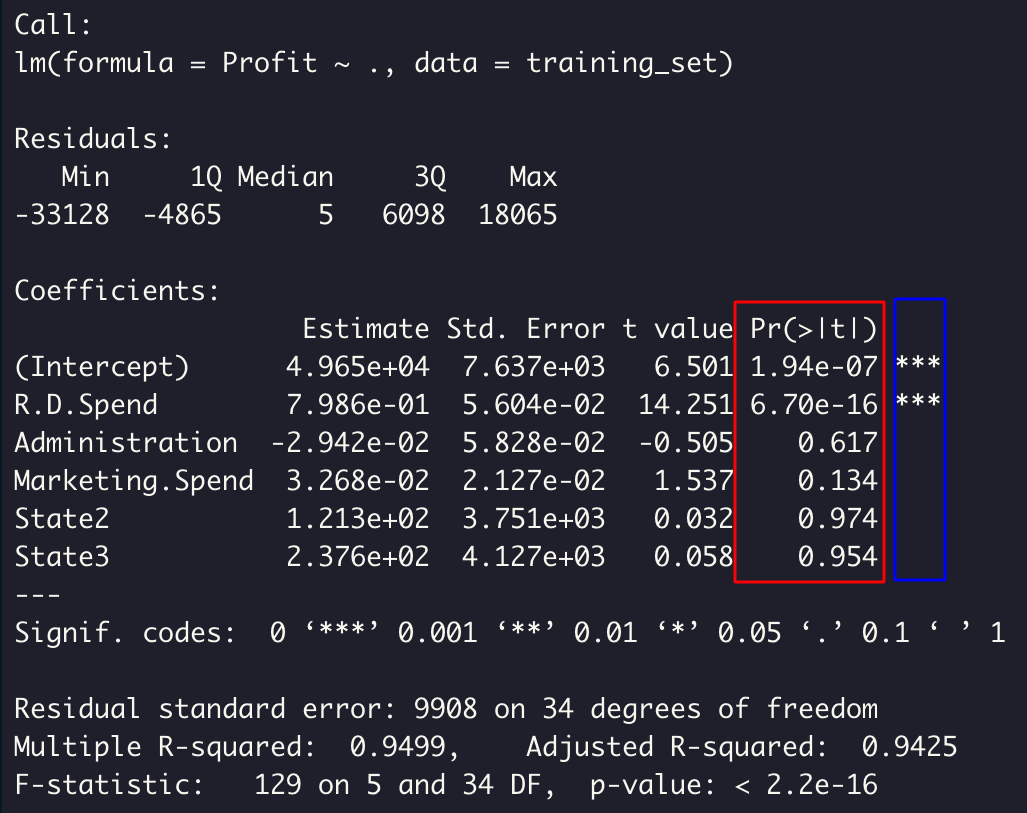
중요한건 Coefficients 파트이다. (State2와 State3은 가변수인데 라이브러리가 자동으로 생성해준 것이다. 가변수의 함정에 빠지지 않은 것 또한 체크하자. 결론: 라이브러리가 다 해준다 굿!)
Coefficients 파트에서 가장 중요한건 마지막 두 컬럼이다.
빨간 박스는 p-value이고, 파란 박스는 significance level(유의 수준, 신뢰 수준)이다.
앞에서도 언급했었지만 p-value가 낮을수록 통계적 유의성이 높다는 것이다. 더 쉽게 말하자면 p-value가 낮을수록 독립변수의 영향력이 크다는 뜻이다.
파란 박스는 그냥 별이 많을수록 중요한 변수라는 것이다. 이 역시 앞에서 다룬 부분이다.
결과를 정리하면, R.D.Spend(연구개발 비용) 변수가 이익에 가장 큰 영향을 끼친다고 해석할 수 있다.
따라서 투자자들은 투자할 스타트업을 고를 때, 이익이 크다고 고를 것이 아니라 R.D.Spend가 가장 높은 스타트업을 고르는 것이 현명할 것이다.
나머지 변수들은 p-value가 0.05보다 크기 때문에 투자 대상을 고려할 때 신경쓰지 않아도 될 데이터들이라는 것도 알 수 있다.
더 나아가서, R.D.Spend만이 유일하게 유의미한 변수이기에 독립 변수를 하나만 고려해도 되고, 이는 즉 다중 선형 회귀를 단순 선형 회귀로 바꿀 수 있다는 뜻이다. (와우!)
이걸 정리하면,
이익은 연구개발 비용과 '비례'한다.
라고 할 수 있다.
이제 훈련 세트를 통해 훈련을 했으니, 이를 테스트 세트에 적용해볼 때가 됐다.
y_pred = predict(regressor, newdata = test_set) 4 5 8 11 16 20 21 24 31 32
173981.09 172655.64 160250.02 135513.90 146059.36 114151.03 117081.62 110671.31 98975.29 96867.03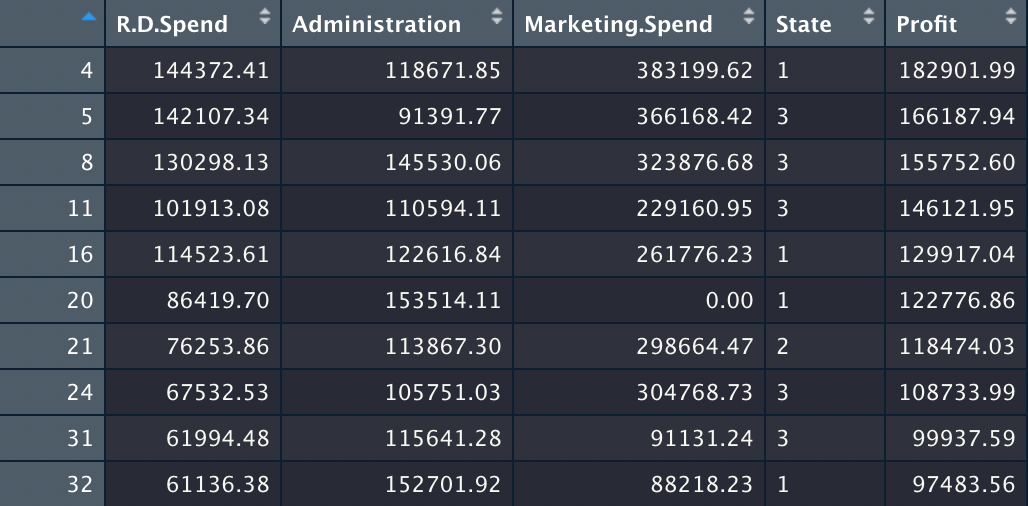
비교를 해보면 예를 들어 4번은 예상 이익보다 더 높고, 5번은 예상 이익보다 낮은 걸 알 수 있다.
'AI > 회귀' 카테고리의 다른 글
| [회귀 - 11] 다항 회귀(Polynomial Linear Regression)란? (0) | 2022.04.24 |
|---|---|
| [회귀 - 10] 후진 소거법 (Backward Elimination) (0) | 2022.04.24 |
| [회귀 - 8] 모델 만들기 (0) | 2022.04.23 |
| [회귀 - 7] p-value (probability value) (0) | 2022.04.23 |
| [회귀 - 6] 가변수의 함정 (0) | 2022.04.23 |




댓글