AI/분류
[분류 - 4] K-NN 분류 실습
Nhahan
2022. 4. 29. 23:45

빠르게 훈련 세트와 테스트 세트를 나누고 스케일링까지 해준다
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased, SplitRatio = 0.75)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set[-3] = scale(training_set[-3])
test_set[-3] = scale(test_set[-3])
훈련 세트를 통해 생성된 K-NN classifier로 테스트 세트를 분류하면 아래와 같은 결과가 나온다.
y_pred = knn(train = training_set[, -3], # 훈련 세트 (종속 변수 제외)
test = test_set[, -3], # 테스트 세트 (종속 변수 제외)
cl = training_set[, 3], # 종속 변수
k = 5, # 이웃의 수
prob = TRUE)
알아보기 힘드므로, 행렬을 통해 결과를 보면,
cm = table(test_set[, 3], y_pred)
cm
총 (57+19)개의 옳은 예측과, (7+17)개의 틀린 예측이 있음을 확인할 수 있다.
훈련 세트를 그래프로 나타내보면,
더보기
library(ElemStatLearn)
set = training_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Age', 'EstimatedSalary')
y_grid = knn(train = training_set[, -3], test = grid_set, cl = training_set[, 3], k = 5)
plot(set[, -3],
main = 'K-NN (Training set)',
xlab = 'Age', ylab = 'Estimated Salary',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green', 'red'))
훈련 세트로 만들어진 K-NN으로 테스트 세트를 그래프로 나타내보면,
더보기
library(ElemStatLearn)
set = test_set
X1 = seq(min(set[, 1]) - 1, max(set[, 1]) + 1, by = 0.01)
X2 = seq(min(set[, 2]) - 1, max(set[, 2]) + 1, by = 0.01)
grid_set = expand.grid(X1, X2)
colnames(grid_set) = c('Age', 'EstimatedSalary')
y_grid = knn(train = training_set[, -3], test = grid_set, cl = training_set[, 3], k = 5)
plot(set[, -3],
main = 'K-NN (Test set)',
xlab = 'Age', ylab = 'Estimated Salary',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid), length(X1), length(X2)), add = TRUE)
points(grid_set, pch = '.', col = ifelse(y_grid == 1, 'springgreen3', 'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1, 'green4', 'red3'))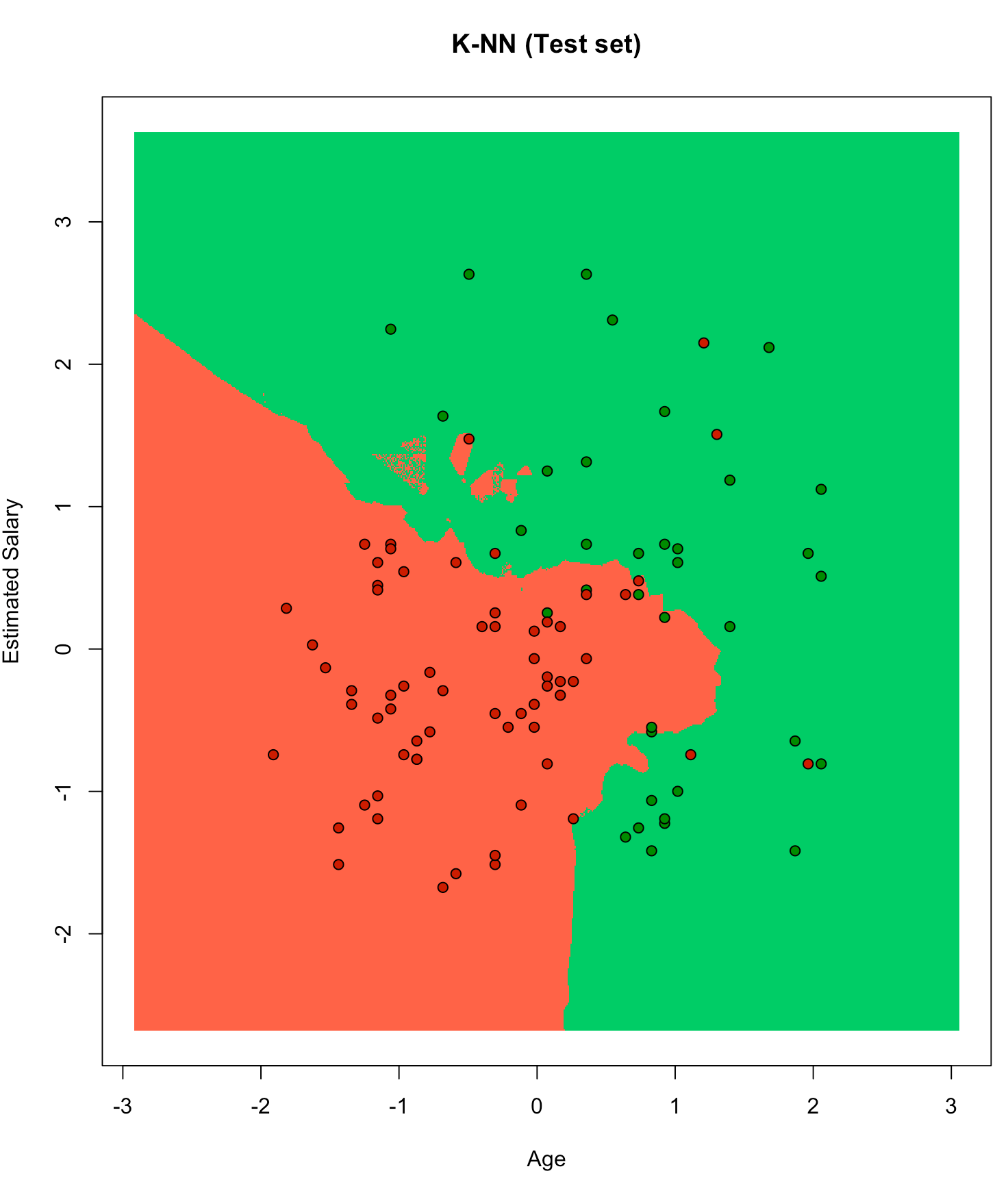
훈련 세트로 만들어진 classifier로 테스트 세트를 검증해도 잘 되었다는 사실보다는,
로지스틱 회귀와는 다르게 비선형적으로 예측 경계가 형성되었고 훨씬 정확하게 데이터들을 분류했다는 점에 주목해보자.