1. 데이터세트를 훈련 세트와 테스트 세트로 나누기

[데이터 전처리]에서 했던 것처럼 아래와 같은 코드를 실행시킨다.
split = sample.split(dataset$Salary, SplitRatio = 2/3)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
[데이터 전처리]에서는 스케일링을 해주어야했지만, 이번에는 회귀 라이브러리가 스케일링을 해주기에 하지 않기로 한다.
2. 선형 회귀 모델 만들기
regressor = lm(formula = Salary ~ YearsExperience, data = training_set)
summary(regressor)위와 같은 코드를 입력하면,
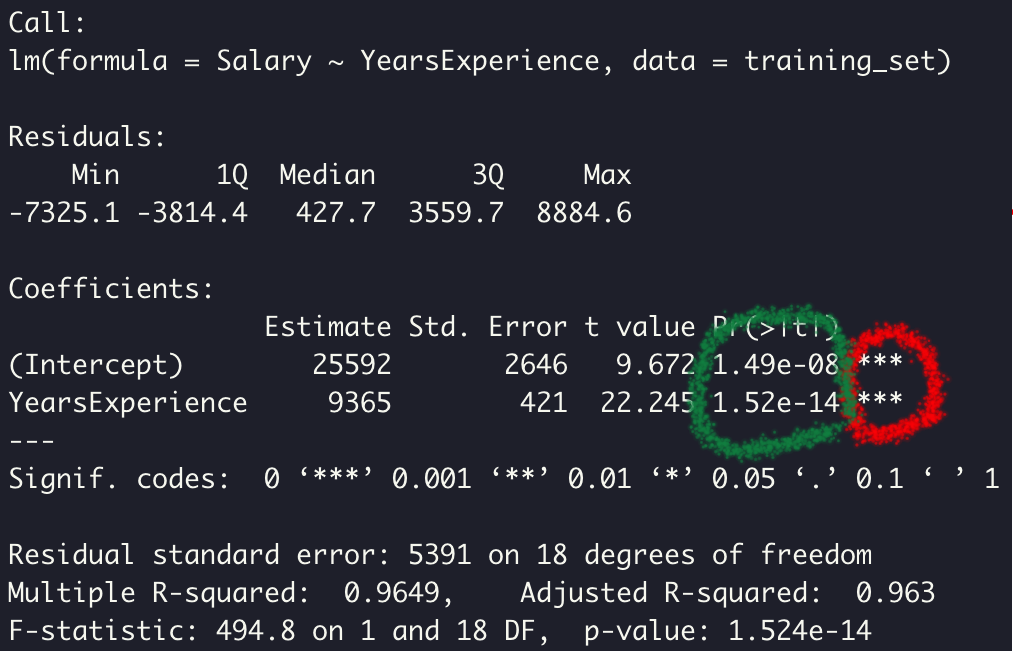
방금 만든 선형 회귀 모델에 대한 정보가 표시된다.
- 빨간원 안에 있는 ***는 데이터의 중요도를 나타낸다.
- 별은 0~3개로 정해지며, 여기서는 YearsExperience 독립 변수가 통계적으로 매우 중요한 요소라는 걸 알 수 있다.
- 초록원 안에 있는 숫자는 p-value이다.
- 이 숫자가 낮을수록 독립 변수의 통계적 중요도가 높다는 뜻이다. 여기서 p-value는 1.52 * 10^-14이기 때문에 매우 낮은 숫자고, 따라서 통계적 중요도가 높다는 것으로 해석할 수 있다. p-value의 일반적인 임계값은 5%로, 5% 미만이면 중요도가 높고, 이상이면 낮다고 할 수 있다.
'AI > 회귀' 카테고리의 다른 글
| [회귀 - 6] 가변수의 함정 (0) | 2022.04.23 |
|---|---|
| [회귀 - 5] 선형 회귀를 설계하기 전에 고민해야할 것들 (0) | 2022.04.23 |
| [회귀 - 4] 단순 선형 회귀 이해도 테스트 (0) | 2022.04.23 |
| [회귀 - 3] 단순 선형 회귀(2) (0) | 2022.04.19 |
| [회귀 - 1] 회귀란? (0) | 2022.04.17 |


댓글